GFS分布式文件存储系统 理论与信息系统运行维护服务实践
引言:分布式文件存储的必要性
在当今大数据与云计算时代,传统的集中式文件存储服务器在处理海量数据、高并发访问及高可用性需求时,已显得力不从心。Google文件系统(Google File System,简称GFS)作为一种开创性的分布式文件存储系统,为大规模数据密集型应用提供了坚实的存储基础。本文将探讨GFS的理论架构,并阐述其在信息系统运行维护服务中的实践应用。
第一部分:GFS的理论架构解析
GFS的核心设计目标是处理大规模、高吞吐量的数据访问,尤其适用于搜索引擎等需要处理海量非结构化数据的应用场景。其理论架构主要围绕以下几个关键理念构建:
- 系统假设与设计原则:GFS建立在“硬件故障是常态而非例外”的假设之上,因此系统设计首要考虑容错性。它通过廉价的商用硬件构建集群,利用软件层面的冗余机制来确保数据的可靠性与系统的持续可用性。其核心设计原则包括:支持大文件(如数百GB)、以追加写(append)为主(而非随机写)的工作负载优化、以及高并发读取的高吞吐量。
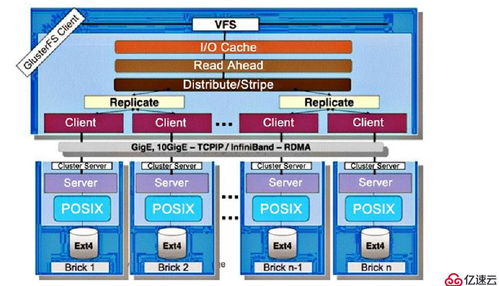
- 核心组件与架构:一个GFS集群主要由三类节点组成:
- 主服务器(Master):负责管理整个文件系统的元数据(如命名空间、访问控制信息、文件到数据块的映射等),协调数据块租约、垃圾回收及数据块迁移。Master是系统的“大脑”,但其设计力求简洁,将数据流的管理下放。
- 数据块服务器(Chunkserver):负责实际存储数据。文件被分割成固定大小(如64MB)的数据块,每个数据块在多个Chunkserver上复制(通常为3份),以实现容错。数据读写操作直接在客户端和Chunkserver之间进行,避免了主服务器的瓶颈。
- 客户端(Client):与应用程序链接的库,遵循GFS协议与Master和Chunkserver交互,为应用程序提供文件系统API。
- 关键工作流程:
- 写操作:客户端从Master获取目标数据块的主副本位置,然后将数据推送到所有副本。主副本负责确定所有副本的写入顺序,确保数据一致性。这种“数据流与控制流分离”的模式,有效提升了写入效率。
- 读操作:客户端从Master获取数据块副本的位置信息,然后选择最近的副本直接读取数据。
- 容错与一致性:通过多副本机制实现高可用。Master通过心跳机制监控Chunkserver状态,并在副本失效时启动复制。GFS提供一种宽松的一致性模型,通过记录追加(record append)操作保证数据的“至少一次”原子写入,非常适合其目标应用场景。
第二部分:作为信息系统运行维护服务的基础设施
将GFS或类似分布式文件系统(如HDFS,其灵感源于GFS)部署为企业信息系统的一部分,对运行维护服务提出了新的要求和机遇。
- 运维服务的新维度:
- 大规模集群管理:运维团队需要管理成百上千台服务器组成的集群,包括硬件监控、操作系统部署、网络配置等。自动化运维工具(如Ansible, Puppet)和监控系统(如Prometheus, Grafana)变得至关重要。
- 数据可靠性与备份:虽然多副本提供了硬件级的容错,但运维仍需关注跨机架、跨数据中心的副本放置策略,以防范机架或数据中心级故障。仍需制定针对逻辑错误或灾难的额外备份与恢复策略。
- 性能监控与调优:需要持续监控Master负载、Chunkserver磁盘I/O、网络带宽、数据块分布均衡性等关键指标,及时进行扩容、负载均衡或参数调优。
- 故障处理与高可用保障:
- Master高可用:原版GFS中Master是单点,现代实践中通常通过主备(如HDFS的NameNode HA)或基于Paxos/Raft协议的多主方案来消除这一单点故障。运维需确保故障切换(Failover)流程的可靠与快速。
- 日常故障响应:Chunkserver故障、磁盘损坏、网络分区是常态。运维体系需要能自动检测、报告并尽可能自动修复(如重新复制数据块)。
- 容量规划与成本控制:运维服务需根据业务增长预测存储需求,进行科学的容量规划。在保证性能与可靠性的前提下,通过数据压缩、归档冷数据、优化副本因子(如对不重要数据降低副本数)等方式控制存储成本。
- 安全与访问控制:在分布式环境中,需强化网络访问控制、认证与授权机制,防止未授权访问。运维需定期进行安全审计和漏洞扫描。
第三部分:挑战与最佳实践
- 挑战:系统复杂性高,调试困难;对小文件存储效率相对较低(元数据压力大);强一致性场景支持有限。
- 最佳实践:
- 自动化先行:将所有部署、配置、扩缩容操作自动化。
- 监控驱动运维:建立全方位的监控和告警体系,实现从基础设施到应用层的可观测性。
- 变更管理:任何对生产集群的变更(如软件升级、配置修改)都必须经过严格的测试和灰度发布流程。
- 文档与知识沉淀:详细记录集群架构、运维手册和故障处理案例,形成团队知识库。
- 与上层应用协同:引导应用开发者遵循GFS的最佳使用模式(如写入大文件、顺序/追加读写),以最大化系统效益。
结论
GFS分布式文件存储系统以其独特的设计哲学,解决了海量数据存储的根本性难题,成为现代大型信息系统不可或缺的基石。对于信息系统运行维护服务而言,管理好这样一个分布式存储基础设施,意味着从传统的单机/小型集群运维,向自动化、智能化、面向大规模集群的SRE(站点可靠性工程)模式演进。深入理解GFS的理论,并将其与扎实的运维实践相结合,是保障数据持续可靠、服务稳定高效的关键。随着技术的发展,虽然出现了对象存储、NewSQL数据库等更多存储范式,但GFS所奠定的思想,仍在持续影响着整个分布式计算领域。
如若转载,请注明出处:http://www.ntpbfnd.com/product/70.html
更新时间:2026-05-30 04:28:07